
Solutions: What Shapes Do Matrix Multiplications Like?
Companion to https://www.thonking.ai/p/what-shapes-do-matrix-multiplications

Note: The answer to question 1 is publicly available, but the answers to the rest are paywalled. However, if you write up your solutions to eaach question and message me, I’ll send you the answer key for free.
Question 1
Let's say I have a [M x K] @ [K x N] matmul. Which one of these configurations will have the best perf? Think about the actual ramifications of tiling! Both matrices are in row-major layout (i.e. K and N are the innermost dimensions)
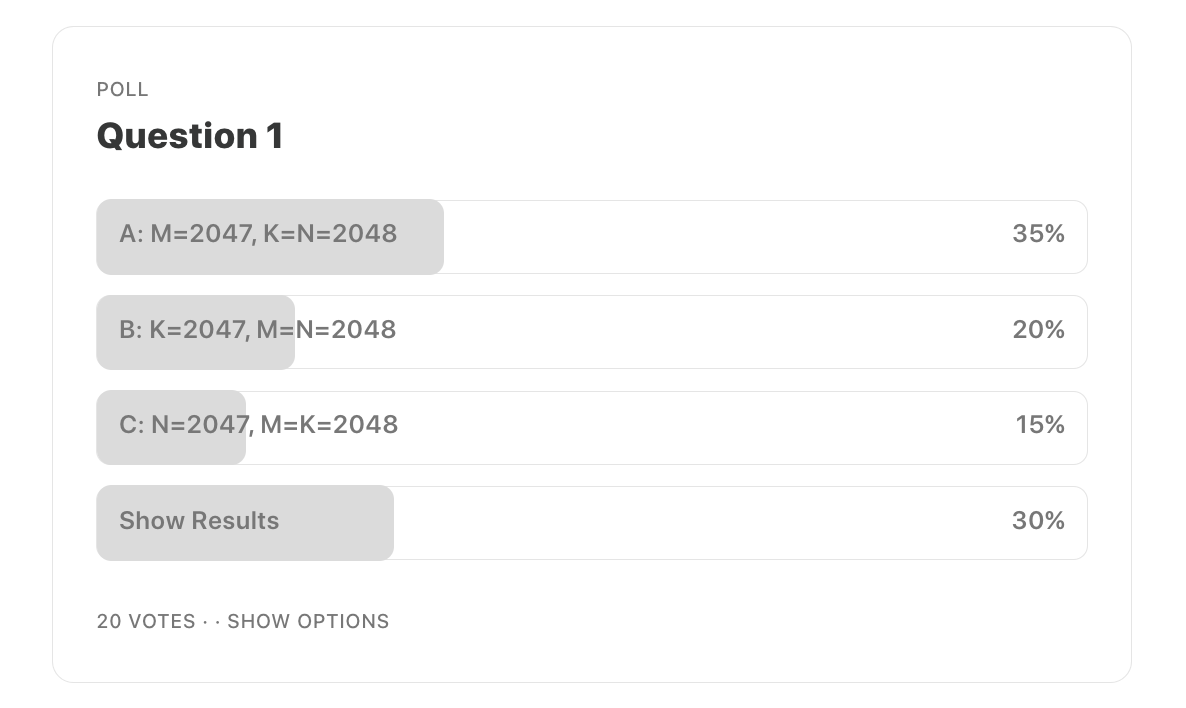
A: M=2047, K=N=2048
B: K=2047, M=N=2048
C: N=2047, M=K=2048
Answer
The correct answer is A. The key to this question is understanding the point about tiling and memory layouts.
When it comes to memory layouts, not all dimensions are created equal. Matrix multiplications are not inherently allergic to odd numbers - the poor performance is for a very specific reason.
In this case, that specific reason, as described here, is that odd shapes lead to unaligned memory layouts. Crucially, however, it must be an odd innermost dimension that leads to unaligned memory layouts.
Before explaining it, let’s have a practical demonstration that A (i.e. M=2047, K=N=2048) is over 2x faster than either alternative. Code can be found here.
import torch
from triton.testing import do_bench
torch.set_default_device('cuda')
for M, K, N in [(2047, 2048, 2048), (2048, 2047, 2048), (2048, 2048, 2047)]:
A = torch.randn(M, K, dtype=torch.bfloat16)
B = torch.randn(K, N, dtype=torch.bfloat16)
print(f"M={M}, K={K}, N={N}")
print(do_bench(lambda: torch.mm(A, B)))
To understand why this occurs, let’s understand how the logical layout and the physical layout look like.
First off, let’s say we have an 8x8 matrix, nicely aligned. Pretend that each cache line is 4 elements long.

This is our ideal situation. The physical layout lines up with the cache lines, each load perfectly uses up every element in our cache line, and the world is at harmony.
However, let’s say we introduce an extra element per row, resulting in an 8x9 matrix.

This one measly element per row throws everything out of balance. Each row no longer starts on a cache line, and when issuing our loads, we can no longer simply load from a single cache line to obtain all the elements we need. (This is all just a restatement of the explanation from here)
However, what happens if instead of adding an extra element per row, we simply add an extra row, resulting in a 9x8 matrix?
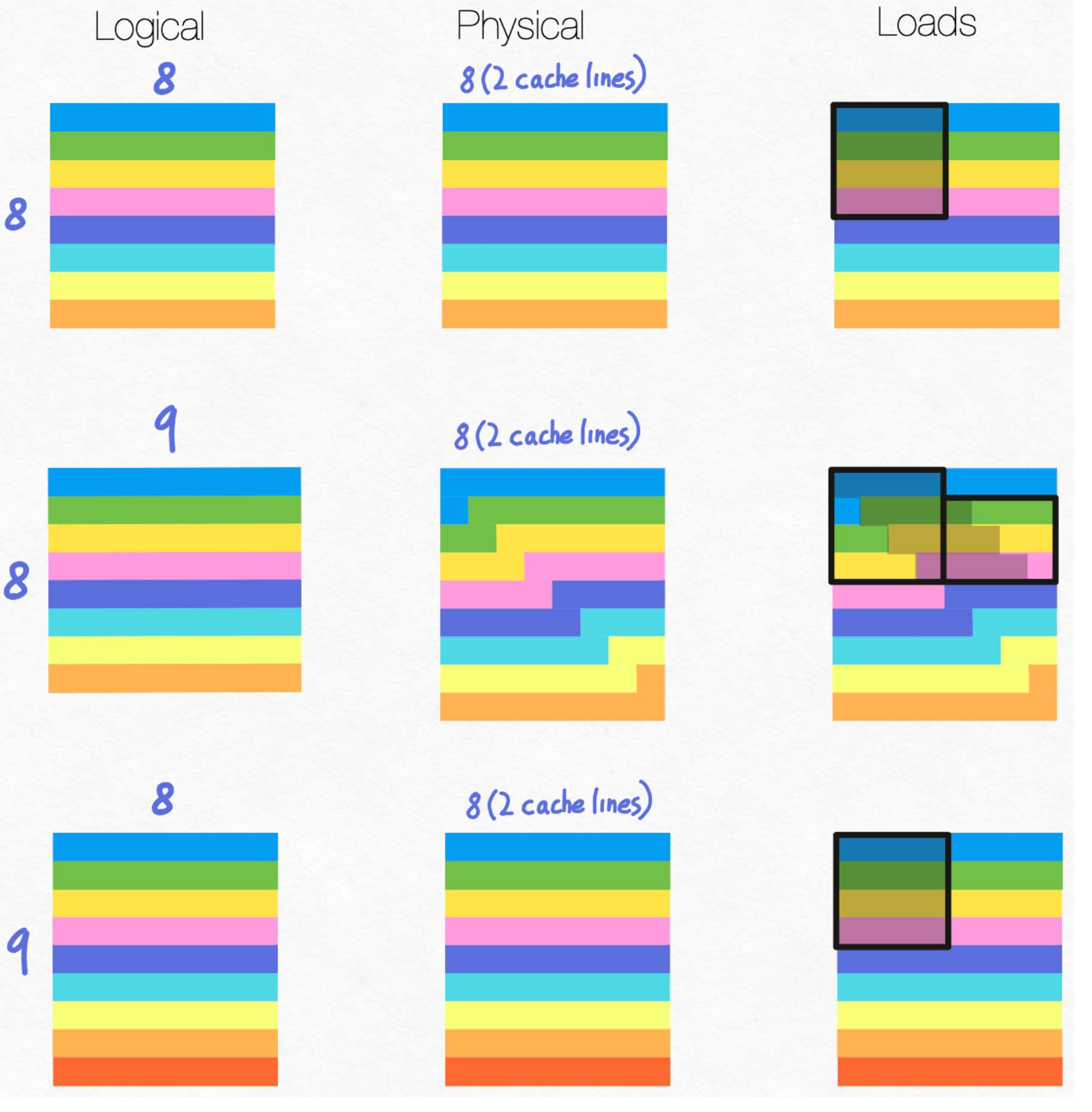
Unlike before, this does not affect the “alignedness” of each row! We do have an extra row at the bottom, and this may lead to some extra computation, but if our matrix was sufficiently large, that computation would be negligible. The important point, however, is that this extra row does not affect the memory layout of the rest of the matrix.
In other words, as long as the innermost size of your matrix is divisible by the cache line size, you’re good to go!
So, armed with our refined understanding of how shapes affect matrix multiplication performance (e.g. only the “evenness” of the innermost dimension matters for memory layouts), let’s look at the question again.
In a matmul, we have A: [M x K] and B: [K x N]. These are both row-major, which means that for K and N are the innermost dimensions of A and B respectively.
A: M=2047, K=N=2048 (the right answer!)B: K=2047, M=N=2048 (Ruled out because K is the innermost dimension of A)C: N=2047, M=K=2048 (Ruled out because N is the innermost dimension of B)
Interestingly, when I originally asked this on Twitter, most people got it wrong.

The substack readers fared much better.
One friend answered that they chose B because “A and C seemed symmetrical, and so B must be the right option, since A and C couldn’t both be right”. Sadly, especially in the world of systems, things that seem identical may not be identical in practice…
I added Question 4 because some people were getting the right answer for Question 1 but for the wrong reasons, so let’s jump ahead and see how our newfound knowledge applies to a slightly modified version.
Question 4
Similar to Question 1, let’s say we have a A: [M x K] @ B: [K x N] matmul. However, now, A is in column-major (i.e. torch.randn(K, M).t()) while B is still row-major. What is the best configuration now?
A: M=2047, K=N=2048
B: K=2047, M=N=2048
C: N=2047, M=K=2048
